🎂 Techブログ公開から1年経ちました
気付いたら1年経っていました
このTech Blogの最初の記事は「データ基盤にガバナンスを効かせるためのDataform概要調査」というものでして、これが2023/02/01公開ということなので、ちょうど1年経ちました!
(本当は先週がそうだったのですが完全に見落としていました)
毎週記事を出し続けるよう意識していることもあって、気付けばかなりのユーザーに見てもらえるようになりまして。
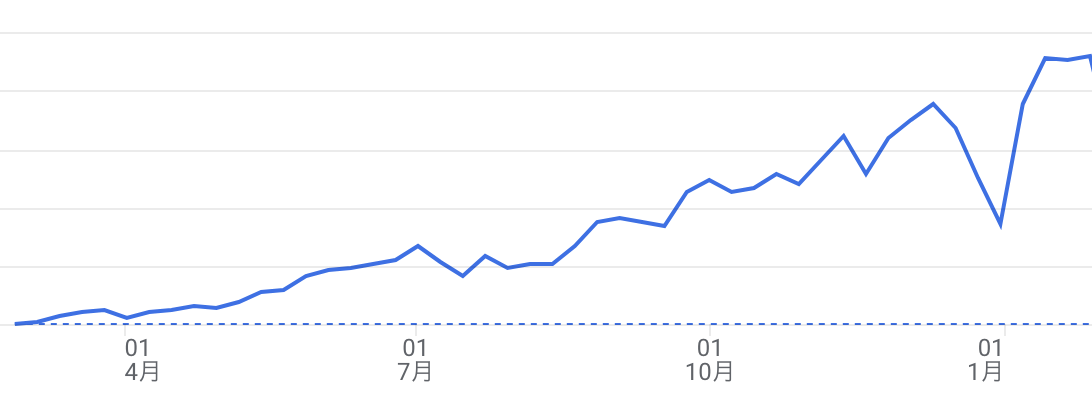
良い感じに右肩上がりでユーザー数も増加しています 👏
(ちなみに右のほうの凹んでいるところが年末年始です。皆さんちゃんと休んでてえらい)
というわけで、折角なので朝日放送グループホールディングス(ABC GHD)のこのBlogでのこれまでのDXに関する発信を振り返ってみようと思います。
もちろん、振り返ってくれるのは、生成AIです。せっかくのTechBlogなので。
前準備
Notionからの記事データのExport
生成AIで色々やってみてもらうための前準備から入ります。
ちょうど本ブログはNotionをCMSとして活用していますので(ご興味があれば最初期の記事「NotionをヘッドレスCMSとして使ってNext.jsでTechブログを作った ①構想編」をどうぞ)、このデータをcsvでエクスポートします。
各記事には概要(meta description)を入れてあるので、今回は記事本文でなく、meta descriptionの情報をもとに振り返って貰おうという魂胆です。そのほうが色々な観点で楽ですしね。
データ項目
これだけでブログのメタ情報の主要項目は全部引っ張って来られます。
簡単にまとめると
-
タイトル
-
カテゴリ
-
タグ
-
発行日
-
著者
-
説明文(meta description)
こんな感じですね。
振り返りとしては十分すぎるデータだと思いますので、これを使って分析をしてみます。
今年の全記事振り返り
LLMに振り返りを依頼する
なんとちょうどいいところにLangchainの create_pandas_dataframe_agent を活用したWebアプリがあるので、これを使って分析します。(突然登場してきたこのアプリ自体はまた本ブログで扱えればと思います。)
データを読ませて、質問を入れます。
質問文全体は以下の通りです。
これは1年分のBlog記事の一覧です。この内容をもとに本Blogの内容について振り返ってください。データの可視化もお願いします。
このアプリでは思考途中の経過も出すようにしています。色々やってくれます。 yyyy-mm-dd 形式じゃないことに気付いて勝手に直してくれたりもするのがアツいですよね。

LLMによるデータ可視化の結果
LLMはカテゴリの分析から入ってくれました。
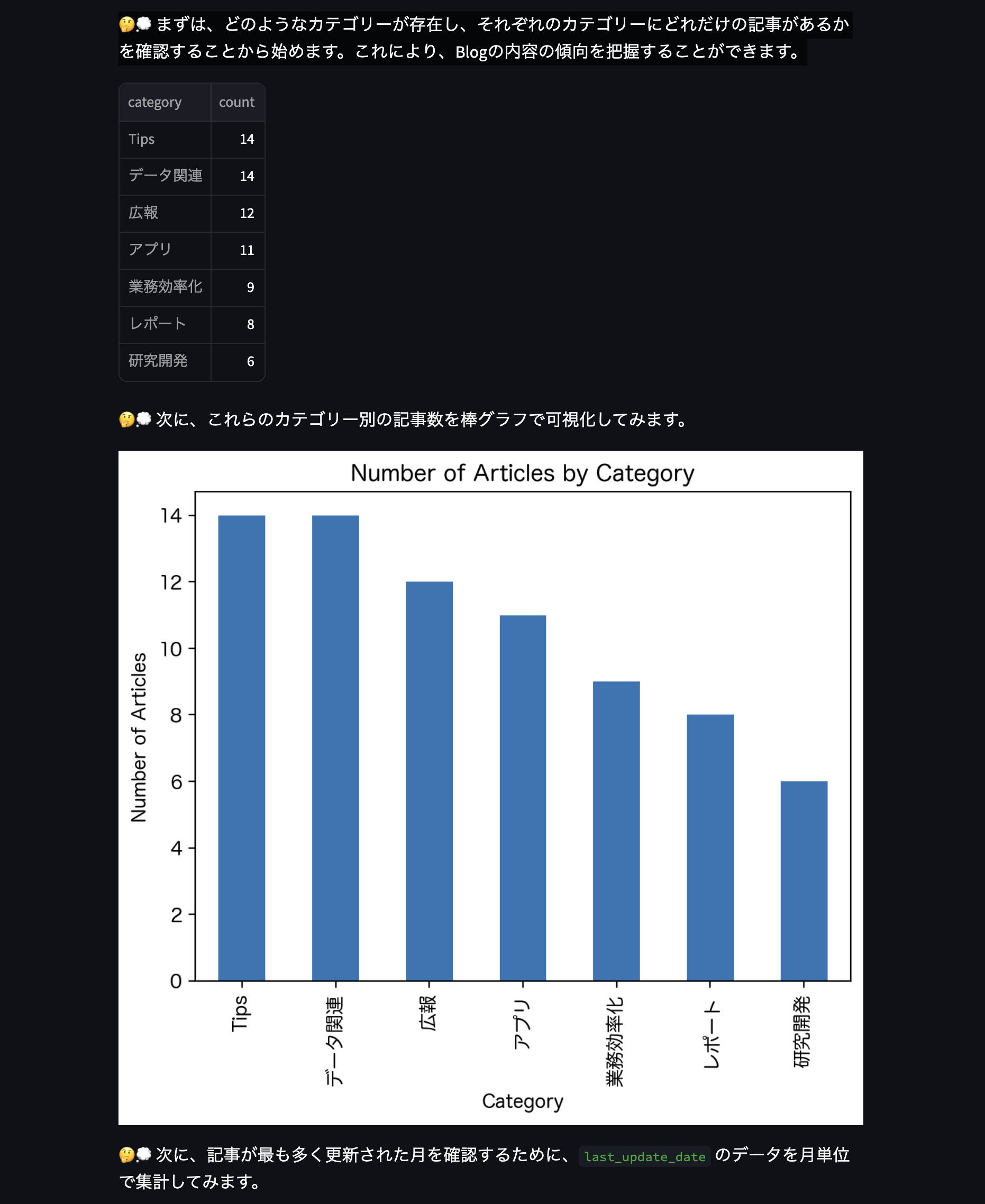
思っていたより満遍なく記事が出ていることがわかります。
もっと何かに偏っているような気がしていましたが…超・簡易的なものですがこうやって可視化されると発見がありますね。
その次には月ごとの傾向をみせてくれました。
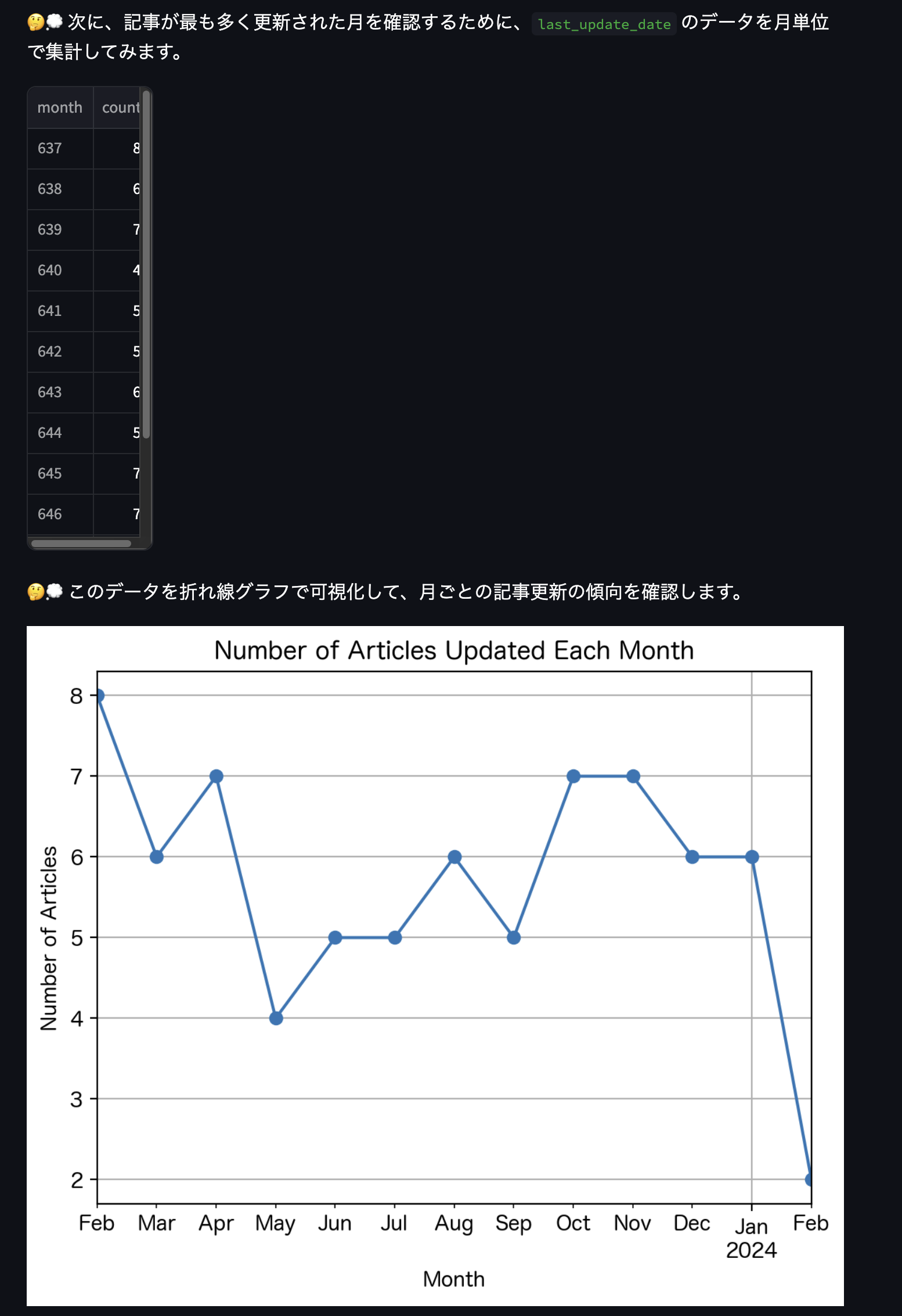
ここもまた、満遍なく出せていることがわかります。
あれ?まだ続きが…
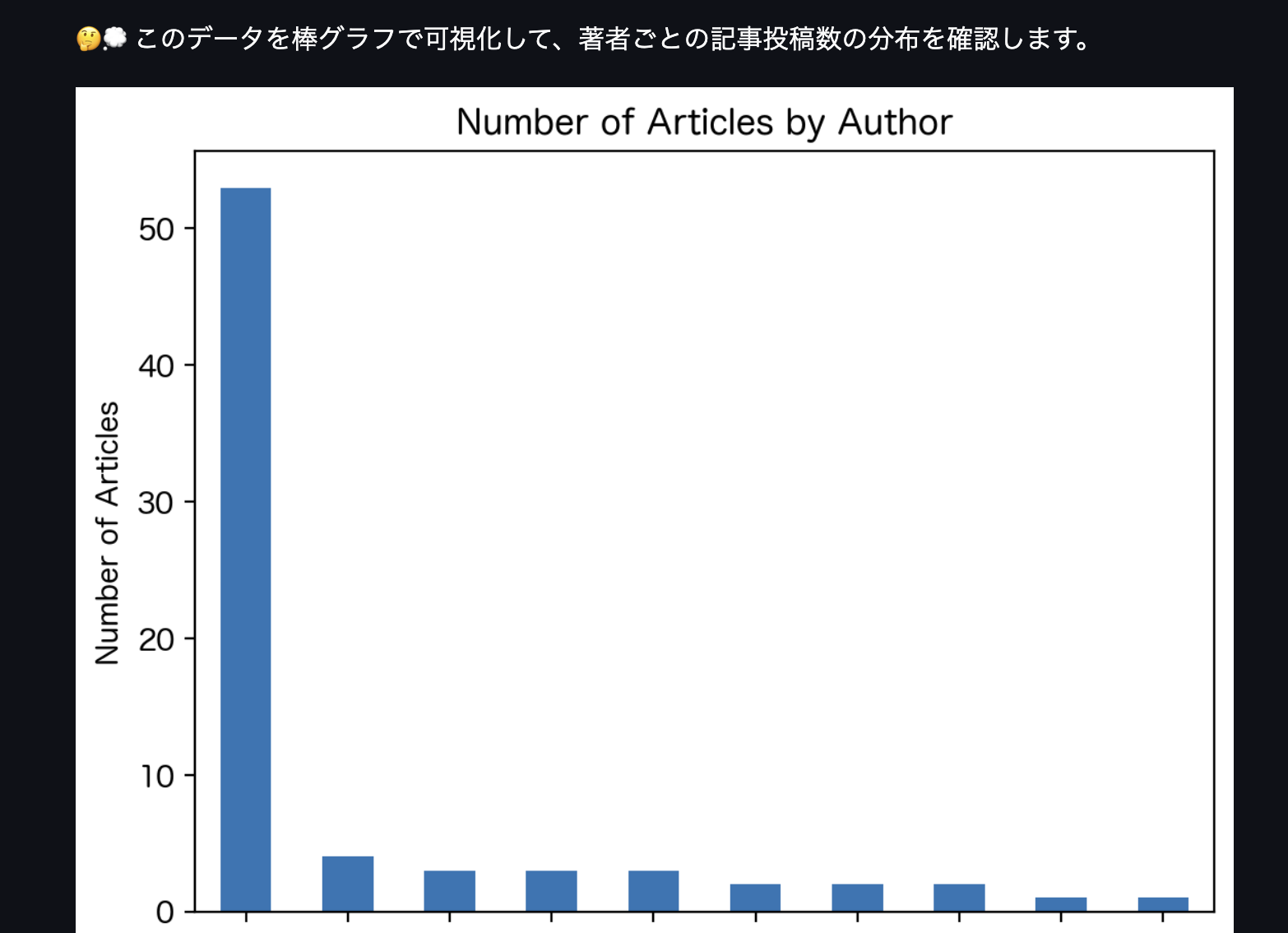
これは見なかったことにしましょう
LLMによる要約
先ほどの質問文だとただの可視化に留まってしまったので、何かインサイトをみつけてもらいます。
質問文はこんな感じでいきます。
説明文・タイトルをもとに、この1年のトレンドやこの朝日放送GHDのブログで特に扱われている内容について教えて下さい。
実行してみます。
1年間のデータになっている旨を伝えていなかったので1年分を抽出する処理まで入れてくれちゃいました。
その後、まず、単語の頻度別で分析をしてくれました。

ここで「一般的な表現」に邪魔されていることに気付いたようですね。
そこで、タグの出現回数上位を出して分析してくれました。

それを踏まえてのまとめです。

間違ってはいないですが、もう少し鋭い切り込んだ要約が欲しい!と思わされます。
descriptionの要約を依頼する
そこで、もう一つだけ追い質問文です。
descriptionの内容を集約し、このブログで扱っている内容を短くまとめてください。

これ、裏側で何をしているかというと、
# 技術的なトピックや具体的な技術名を含む単語を選び出す tech_words = [word for word, count in word_counts.items() if word in ['GitHub', 'Python', 'Docker', 'Google', 'データ', 'API', 'Notion', 'Git', 'コマンド', '開発環境']] # 選び出した単語の出現回数をカウント tech_word_counts = Counter(tech_words) # 最も頻出する技術的な単語トップ10を取得 tech_word_counts.most_common(10)
のようなことをしているようです(ちょっと恣意的すぎる笑)
そんなこんなの処理があって、生成AIによるまとめです。

やはり最初の可視化で見たとおり、思った以上に内容が満遍ないことで、サマリもありきたりな感じになりますね。質問文次第ではもう少しうまくやれそうな感じもしますが…
なお、「Google Cloud」が多いのは、データ系の記事で必ず登場しているからであろうと推察されます。
生成AIによる分析を受けて
以上を踏まえて、このブログの「人間(私)」による振り返りです。
このブログ自体のCMSやホスティング等の設計を含めて暗中模索しながら1年続けてきましたが、満遍なく記事を出せていることが確認出来て良かったです。(今年は著者の偏りも減って満遍なくなるとさらにいいですね。)
1年前との技術トレンドの変化という意味では、何よりもこんなことを手軽に出来るようになるほどLLMまわりの環境が充実し、また、進化しているとは思ってもみませんでした。
2周年を迎える頃にはさらに進化していることを期待せざるを得ません。
まとめ
今回はTech Blogの1周年記念でブログ記事の振り返りを行いました。
データのExportも含めてNotionでCMSを作っている利点を活かして行えた分析でなかなかに楽しんで手を動かせました。
この突然登場したLLMによるデータ分析アプリについてはまた今月の後半か来月の頭くらいに扱えればと思います。
やはりこの1年のホットトピックはとにかく生成AIだったかと思います。
ここまでの試行錯誤を踏まえると、このような自前データを使ってのLLMの活用については
-
サマライズや創造性発揮においてはフル活用できる(今回のケース)
-
調査・検索目的であればembeddingしたうえで関連するドキュメントやファイルを引っ張ってくるだけで充分(情報をあえて生成する必要は無い)
という認識です。(あくまでも2024/02の時点では)
embedding一つとってもほんの2年前にはこんな手軽に試せる状況ではなかったように思うので、やはり環境の劇的な変化には驚きますよね。
さて、2年目に入った本ブログですが、これからも継続して更新していければと思います。
エンジニアにとっても実は魅力的かつ本格的なこともやれるABCというイメージをぜひ皆さんに持っていただけるよう、新しい知見発見にも注力していきますので引き続きよろしくお願いします!
